VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION
Karen Simonyan & Andrew Zisserman
Very Deep Convolutional Networks for Large-Scale Image Recognition
In this work we investigate the effect of the convolutional network depth on its accuracy in the large-scale image recognition setting. Our main contribution is a thorough evaluation of networks of increasing depth using an architecture with very small (3x
arxiv.org
중요 concept (CONCLUSION)
- VGG모델 이전, 이미지 분류에서 퍼포먼스가 좋은 Conv. Network를 활용한 모델에서 사용한 7*7, 11*11의 filter를 사용하지 않고, 비교적 작은 receptive field를 갖는 3*3크기의 작은 필터만을 사용하였다.
- 모든 layer에 작은 3*3 filter만 사용함으로써 이전보다 더 깊은 conv. layers를 쌓아 16-19layers 신경망 모델의 학습에 성공할 수 있었다.
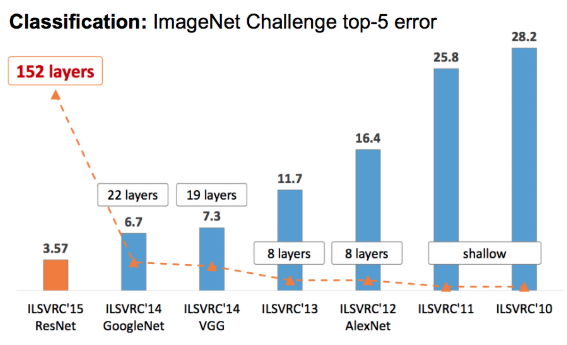
Classification Task에서 이전 모델과 달리 더 깊은 층으로 구성되어 있다. 준우승을 차지하였지만, 구조가 더 쉬워 복잡한 구글넷보다 더 인기가 있다.
CONVNET CONFIGURATIONS
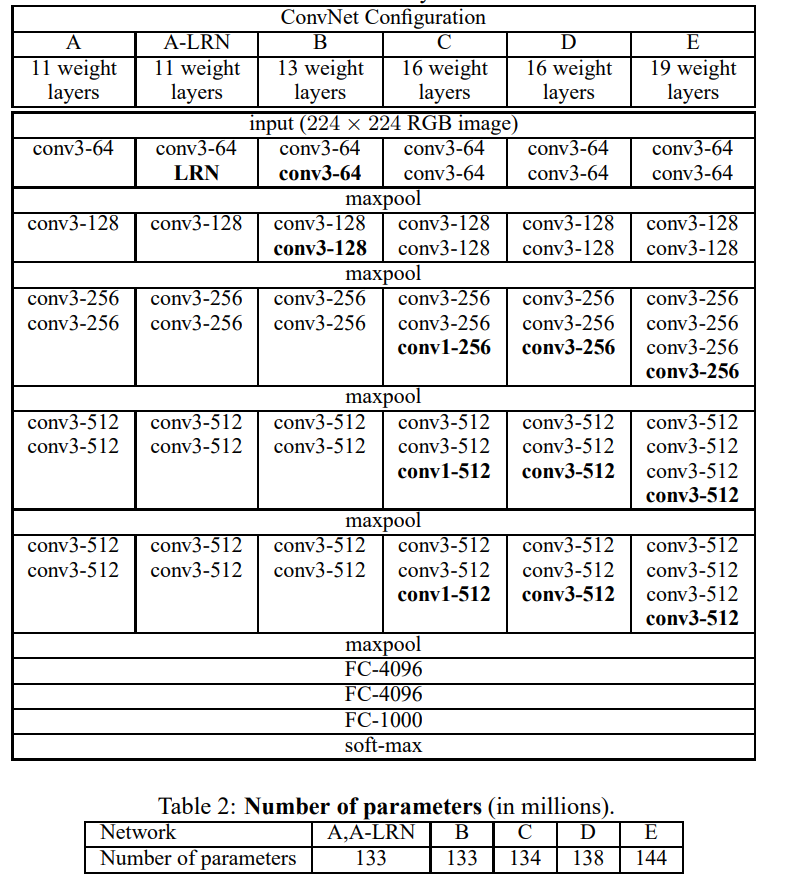
ARCHITECTURE
224*224 RGB image를 사용
전처리로는 training set의 평균 RGB값을 subtraction
filter는 가장 작은 사이즈인 3*3filter를 사용 (16weight layer에서는 1*1 convolution filter도 사용한다)
convolution stride는 1 pixel, padding 1 pixel로 고정하여 입력 이미지의 spatial resolution이 유지된다
( ((입력이미지 + 2*padding - filter) / stride) + 1 = 입력이미지 )
5번의 2*2 pixel window, 2 stride인 max pooling
( 입력이미지 / 2 )
모든 hidden layers에서는 activation function으로 ReLU를 함
feature extraction 후 두 개의 4096 channels Fully-Connected layers, 마지막으로 한 개의 1000 channels Fully-Connected layers가 온다. 이로써 각 class마다 한 개의 채널을 가져 총 1000개의 채널을 가짐.

1*1 convolution filter? 행과 열의 크기 변화없이 Channel의 수를 조절, weight&비선형성 추가
CONFIGURATIONS
위 Table1과 같이 A-E의 각기 다른 ConvNet이 있다. 각각은 11weight layer(8conv. / 3 FC layers)에서 19 weight layers( 16conv. / 3 FC layers)까지 존재한다.
Conv. layers의 너비(채널의 수)는 첫 번째 layer에서 64에서 시작하여 512까지 증가한다.
Table2는 각 configuration의 파라미터 수를 보여준다. 이는 ConvNet의 깊이를 생각해보았을 때 깊이가 얕고 conv. layer의 width와 receptive field가 큰 network보다 weight의 개수가 많지 않은 수 이다.
DISCUSSION
ILSVRC-2012, ILSVRC-2013에서 사용된 최고 성능의 configurations과 꽤 다르다. 이들은 첫 번째 conv. layer에서 상대적으로 큰 receptive fields를 사용했지만(11*11 with stride 4, 7*7 with stride 2) 우리는 철저히 모든 input과 convolve되는 net에 작은 receptive fields(3*3 with stride 1)를 사용한다.
pooling이 없는 3*3 conv layers의 stack은 5*5의 receptive fields효과, three stacks는 7*7의 receptive fields효과를 갖는다고 보기 쉽다.
7*7대신 3*3 conv. layer의 stack을 사용함으로써 우리가 얻어내고자 하는 것
-> 1. 한 개가 아닌 3개의 non-linear rectification layers를 사용함으로써 decision function의 비선형성 증가
-> 2. 파라미터의 수를 감소시킬 수 있다. 만약 입력과 출력의 채널 수를 C라 하면 3*3 conv.는 27C^2, 7*7 conv.는49C^2으로 7*7 conv. filters가 81% 더 많은 파라미터가 필요하다.
Table1의 C configuration에는 1*1 conv. layer가 있다. 이는 conv. layers의 receptive fields에 영향을 미치지 않으면서 decision function의 non-linearity를 증가시키는 방법이다. in our case, 비록 1*1 convolution의 경우 입력과 출력의 채널이 같은 동일한 dimensionality의 공간에서 linear projection이지만 rectification function을 통해 non-linearity가 introduce된다.
1*1 conv. layers는 "Network in Network"로 활용되고 있다.
CLASSIFICATION FRAMEWORK
TRAINING
mini-batch gradient descent를 사용하여 다항 logistic regression을 최적화함. 이때 사용된 hyperparameter와 최적화 기법은 아래와 같다.
- Momentum 0.9
- weight decay(L2 norm)
- learning rate : 초기 10^(-2), validation accuracy가 향상되지 않으면 1/10
- Dropout : 0.5
가중치 초기화는 딥러닝 학습에서 안정성에 영향을 줄 수 있기 때문에 중요하다 따라서 다음과 같이 학습하였다.
- 무작위로 초기화된 값으로 얕은 11 layer 네트워크를 우선적으로 학습
- 학습된 값에서 이후 깊은 모델을 학습할 때, 처음 4개의 conv. layer와 FC layer에 적용
- 나머지 layer에서는 임의의 값으로 초기화
- 이때, 임의로 초기화된 값은 정규분포를 따름
학습 시 입력 이미지 크기는 224*224의 크기로 고정한다. 이때 multi scale training을 하는데, isotropically-rescaled image를 샘플링함으로써 한정적인 데이터 수를 늘리고, 하나의 오브젝트의 variation에 강인하게 하였다. 이는 single scale training보다 classification accuracy가 더 높다.
TESTING
test를 할 때에는 Fully Convolutional Network를 테스트한다. 이 network는 마지막 FC layers를 Conv. layers로 바꾼 것이다. 첫 번째 FC layer는 7x7 conv layer로 마지막 두 FC layer는 1x1 conv layer로 변환함으로써 입력 이미지의 크기 제약이 없어지게 하였다. 이를 통해 image classification accuracy를 개선할 수 있다.
'딥러닝' 카테고리의 다른 글
| 오픈소스 LLM 쉽게 이용하는 사이트 모음 (0) | 2024.04.26 |
|---|---|
| Spatial Transformer Networks (0) | 2022.03.20 |
| ResNet 읽기 (0) | 2022.03.10 |
| 딥러닝 개념 (0) | 2022.02.22 |



댓글